
我们正在进入一个生成式AI加速普及的新时代。今年8月,国务院下发了《关于深入实施“人工智能+”行动的意见》,其中重点提到要尽快实施“人工智能+”产业发展,培育智能原生新模式新业态,推进工业全要素智能化发展,加快农业数智化转型升级,创新服务业发展新模式。
前不久,知名研究机构IDC做了一个非常乐观的预测:2025-2029年,预计中国生成式AI市场的复合增长率将高达47.9%,大大高于同期GDP的增长率;2029年,市场规模将达到457.6亿美元。
高速增长的AI市场,需要更加坚实的AI基础设施。前不久发布的《中国人工智能应用发展报告(2025)》认为,未来十年,AI 的发展可能需要100万倍的算力支撑。
如何保证充足的AI基础设施供应?在12月5日北京举行的“异构智算 本地引擎”2025联想异构智算产业联盟高峰论坛暨AI算力基础设施新品发布会上,联想集团副总裁、中国基础设施业务群总经理陈振宽给出了关键答案——“联想AI工厂”。

联想集团副总裁、中国基础设施业务群总经理陈振宽
智算中心呼唤AI工厂
“AI工厂”最早由Marco Iansiti和Karim R. Lakhani 在2020年出版的《AI时代的竞争》中提出,它通过紧密集成计算、存储和网络元素,为人工智能工作负载优化整个系统,使人工智能的使用具有操作性。

AI工厂之所以被称为“工厂”,是因为它与物理工厂相似,只不过物理工厂生产的是物理产品,而AI工厂生产的则是智能,我们能够利用这些智能操作AI模型、IT系统和其他资产。
我们为什么需要AI工厂?因为要支持高速发展的生成式AI,就需要全新的智算数据中心(AIDC),而传统数据中心已经力不从心。
两种数据中心的对比
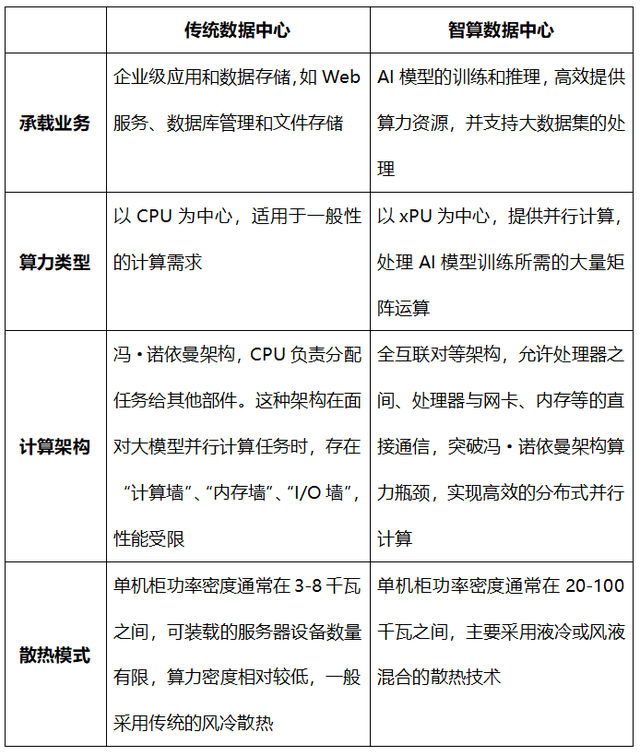
虽然我们迫切需要全新的智算数据中心,可是产业界却并没有做好准备。
以上表中的“计算架构”为例,在采用全互联对等架构的智算数据中心当中,不再是CPU统揽全局调动四方,而是需要多达几种甚至十几种不同处理器(CPU/GPU/xPU)的直接通信。在强调自主创新的中国,处理器的类型尤其多样,这个问题也更为明显,而之前却并还没有一个很好的解决方案。
再比如,随着AI应用的大发展,使得南京大学等高等院校的科研项目从以CPU为主的科学计算,转向以深度学习和AI大模型为主的科学智能计算。但是,由于GPU服务器的成本远高于CPU服务器,南京大学在数据中心扩容升级的时候,仍然只能以CPU计算节点为主,而这能否满足南京大学长期的科研需求,仍然是个问题。
而且,伴随着过去二十多年互联网的大发展,传统数据中心的建设、运维已经形成了一整套非常成熟高效的模式。你会发现,与已经采用“现代化大工厂”模式的传统数据中心相比,智算数据中心的建设和运维仍然还是“手工小作坊”模式。

因此,我们迫切需要智算数据中心的“工厂化”。此次推出的“联想AI工厂”解决方案,就是要构建一套可管理、可复制且支持持续运营的标准化体系,重塑AI应用的开发与部署流程,将原本复杂且孤立的AI开发任务转变为标准、高效的现代化“AI生产线”。
具体到智算数据中心,联想已经成功搭建了“一横四纵”的战略布局。下面,老冀就给大家做个详细解读。
“乐高”服务器
联想的“一横四纵”中的“一横”是万全异构智算方案,“四纵”则是服务器、存储、数据网络、软件及超融合。其中,服务器可谓“纵”中之“重”。
在12月5日的发布会上,联想发布了堪称“核武级”的首款高端大模型训练AI服务器——联想问天 WA8080a G5新品。
谈起这款新品最大的特点,联想中国基础设施业务群服务器事业部总经理周韬认为,是为了满足客户的多样化需求而倒逼出来的模块化设计。

联想中国基础设施业务群服务器事业部总经理周韬
周韬和他的团队发现,过去设计一个新的服务器产品,基础架构定下来以后,可以沿用好几代。而现在,AI技术发展实在是太快了,刚过一年,原来的架构就不能支持新的发展了。
为此,这次在联想问天WA8080a G5上,他们直接把机箱加到了10U,能够支持超过1000瓦的单GPU。要知道,目前单GPU的功耗基本上也就是在500-600瓦的水平,10U将能够支持未来两代甚至更多代产品的功耗。
联想问天WA8080a G5的CPU主板、GPU主板以及中间背板,都做成了模块化的组件,尽量让这些模块互相能够通用,从而降低了重新开发组件的成本。
这款AI服务器还构建了高效灵活的“1+3+N”,也就是采用1个系统架构,兼容3种不同的CPU,还兼容多家厂商的GPU,只要它们支持主流的OAM2.0。这就在很大程度上适应了国内市场特别是信创相关的需求:毕竟,国内市场上,AI服务器的GPU供应商除了英伟达等国际厂商之外,还有诸多国产厂商。
有了“1+3+N”架构和模块化设计,联想问天 WA8080a G5就能够快速满足国内企业客户由于采用不同芯片导致的不同需求。无论是哪家厂商的GPU,只要符合OAM2.0标准,直接放进机架里就能做适配,极大地降低了服务器的适配时间。
此外,联想问天WA8080a G5还同时兼顾风冷和液冷双模散热方案,有着极强的适应能力。
这样的服务器,是不是有点像通过不同组件的自由组合、创造出千变万化造型的“乐高”?
有了“乐高”服务器作为主力,再加上同样能够灵活配置的存储、数据网络、软件及超融合产品,共同组成完整的AI基础设施,联想为“AI工厂”打下了稳固的支柱。
算无遗“场景”,才“万全”
打造AI工厂,光有稳固的支柱当然不够,还需要同样稳固的屋顶,而且这个屋顶还要适应各种不同的支柱组合。这个屋顶,就是联想打造的“一横”:联想万全异构智算平台(以下简称“万全平台”)。
联想中国基础设施业务群战略管理总监黄山表示,自从去年4月诞生的第一天起,万全平台就在不断加大对AI原生技术栈的支持力度、广度和深度。

联想中国基础设施业务群战略管理总监黄山
万全平台1.0和2.0发布的时候,AI的算力瓶颈主要还是集中在预训练领域,因此,黄山带领的万全平台团队把主要优化方向放在了提升底层算力上面,实现了20-30%的训练效率提升。
去年12月,DeepSeek横空出世,一口气发布了DeepSeek-V3基座大模型、DeepSeek-R1推理模型、Janus-Pro多模态大模型,达到了OpenAI同类型模型的同等水平,训练成本却只有5%,运行成本更是只有3%。更重要的是,DeepSeek还公开了模型训练中对于算力优化的方式和方法。
万全平台团队发现,DeepSeek的很多方法都能够用在推理上。在今年5月发布的万全平台3.0中,他们新增了AI推理加速算法集、AI编译优化器、AI训推慢节点故障与自愈系统、专家并行通信算法四大突破性创新技术,直击大模型应用落地的关键痛点,并为DeepSeek R1/V3等千亿级大模型提供更高效的运行环境,不断突破算力效率极限。
他们也花了不少精力去解决国产GPU适配的难题。“今年上半年,我们广泛、彻底地把国产GPU给跑起来了。”黄山透露。
而这次发布会上推出的万全平台4.0,又解决了四大AI场景中的诸多难题。
第一个是预训练场景。如今的大模型,需要训练的文章越来越长,已经出现了六七万字甚至20万字的文章,产生了128K的长序列。长序列的预训练需要大负载,需要并行策略的优化。万全4.0通过长序列并行优化,模型训练时间可缩短35%。
第二个是后训练场景。大模型正在加紧从单纯的语言向多模态发展。由于每种模态向量计算的算法都不一样,要调的算力不一样,出来的Token也不一样,这就需要进行不同类型Token之间的匹配。万全4.0针对通义千问等主流大模型专门做了计算引擎优化、小样本强化学习、训练自动并行,可使训练时间缩短50%。
第三个是推理场景。大模型也正在从训练转向推理,大规模、高并发的推理,需要高速网络的支持。如今,RoCE网络得到了众多厂商的支持,正在成为主流。但是,如果不做负载均衡的话,RoCE网络的带宽利用率会呈现指数级下滑,而且用传统负载均衡解决不了。万全4.0打造了一套RoCE网络专用的负载均衡优化方案,将带宽利用率提升了60%,通信原语性能提升30%,大模型推理性能提升30%。
第四个是超智融合计算场景。之前,国内已经建成了不少的超算中心,如今大规模转向智算中心,如何将过去的投资利用起来?联想首先在吉利汽车做了超智融合的实践,取得了不小的成果,实现了两者的算法融合。万全4.0可支持国际和国内硬件生态,完成从底层架构到算子的全面优化,同时新增超16个制造业应用的作业模版和脚本,实现高效超智融合。

黄山表示,万全4.0已经为众多算力场景提供全面支持:在国家级高质量AI集群场景中,联想与东数西算第一大智算枢纽紧密合作,在千卡训练场景中将MFU从30%提升至60%;针对模型本地部署的企业AI基础设施场景,全速运转满血版DeepSeek R1模型极限吞吐量已经超越12000 Tokens/s,不断刷新性能行业记录。在高校科研场景中,联想助力北京大学建设多模态跨尺度生物医学成像设施科研场景HPC/AI融合算力管理平台,持续稳定地输出算力,并不断地突破计算效率。
训推服务做“标兵”
有了“一横四纵”,一家合格的样板“AI工厂”算是建立起来了。不过,联想觉得这仍然不够,如果能够把“AI工厂”的建设过程总结成手册和标准,以后再建千家万家的“AI工厂”,不就容易了许多?
正是基于这个目的,在这次大会上,联想还携手众多产业伙伴,重磅发布了业内首个模型训推服务标准《信息技术算力服务高性能训推服务能力要求》验证成果。

联想作为主编单位,全程参与了标准制定过程。据了解,制定此标准意在为高性能模型训推服务建立统一的能力标尺,此举有利于规范服务市场、牵引技术升级,降低各行业AI应用门槛,推动算力服务从“资源交付”向标准化、高质量的“能力交付”演进,从而加速智能化转型。
中国电子技术标准化研究院软件应用与服务研究中心云计算研究室主任陈志峰认为,该标准的核心价值在于弥补业界高性能训推服务能力规范标准空白,既为企业提供统一架构参考,更推动AI生产从零散探索走向标准化、规模化,加速行业智能化转型。

中国电子技术标准化研究院软件应用与服务研究中心云计算研究室主任陈志峰
作为该标准的主编单位和核心贡献者,联想并非仅仅是规则的制定者,更是率先的实践者与验证者。其发布的验证成果,全面展示了其AI服务器、万全异构智算平台在满足并超越该标准要求方面的卓越能力。
在异构算力调度与一体化范式方面,联想的智能算力平台成功验证了标准的统一抽象与调度要求,实现了训练与推理任务的资源共享与无缝流动。
在通信网络优化方面,通过集成先进的在网计算技术和自研的RoCE网络自动化调优系统,验证了标准中对无损网络和通信性能的严苛指标,实现了高性能网络的“开箱即用”。
在高性能推理方面,联想基于其推理引擎,成功部署并验证了PD分离架构与KV-Cache优化技术,在复杂模型上实现了吞吐量与响应时间的显著优化,完全符合标准对SLA保障的要求。
该标准的制定与验证成果的发布,为满足高性能训推的算力服务质量提供了统一的衡量标准,有助于规范性能指标和服务质量,并指引算力基础设施与服务商向体系化、高性能、高可靠的方向演进,推动整体产业升级。
AI工厂推动AI普惠
正是因为此前在AI原生技术栈上已经有了丰富的积累,再加上“一横四纵”战略的加速实施,虽然联想刚刚发布“联想AI工厂”整体解决方案,但是其中的很多产品和解决方案,已经在企业中得到了成功验证。
举个典型的例子。随着人工智能大模型的发展,南京大学的高性能计算中心开户课题组已经不仅仅是来自传统的化学化工、大气科学、地球科学、物理学院等传统理工科“算力消耗大户”,也有来自商学院、社会学院等相关文科学院的研究课题。由此,南京大学高性能计算中心也将会从传统的科学计算中心,逐步演进为科学智能计算中心。
作为核心供应商的联想,已经做好了准备。为了帮助南京大学应对高性能计算集群与智能计算机群并存的局面,联想万全易购智算平台可以统一纳管异构算力,能够更好地应对超制融合的管理挑战,实现HPC集群与智能计算机群统一的管理和调度。
除了南京大学之外,联想也为北京大学、上海交通大学、南方科技大学等数十所高校打造了高性能计算平台和智算平台。
再举个例子。今年2月,爱尔眼科与联想合作,率先在行业内实现了本地部署DeepSeek满血版大模型并引入联想万全AI一体机方案。爱尔眼科数字人“爱科”(Eyecho)正式升级接入DeepSeek-R1推理模型,实现智能问答、医学科普及患者互动的精准性与效率提升,用户体验全面优化。
在AI基础设施的部署上,联想就采纳了“AI工厂”的理念。联想万全AI一体机基于联想问天 WA7780 G3 AI大模型训练服务器,内嵌Transformer Engine,支持高达100并发。联想万全AI一体机还凭借软硬件的深度适配,大幅简化了DeepSeek大模型的部署流程。
此外,联想万全AI一体机搭载8张96G显存高性能GPU,并支持FP8优化,单机可部署671B参数的DeepSeek-R1满血版大模型,并可通过两台集群部署FP16量化模型,满足更复杂的AI应用需求。FP16精度更高,能更精准地处理知识库内容,确保答案的准确性和专业性。
从联想此前的诸多AI成功实践也可以看出,“联想AI工厂”顺应了企业的需求,也符合我们这个时代的要求,可谓前景广阔、大有可为。

如今,AI工厂已经成为全球产业界的共识。就在今年6月巴黎GTC大会上,英伟达创始人兼首席执行官黄仁勋发表主题演讲,宣布将在德国建设全球首个工业人工智能云设施“AI工厂”,“在人工智能时代,每个制造商都需要两个工厂:一个用于制造产品,另一个用于创造驱动这些产品的智能。”
全球范围内,各国政府与企业都在竞相建设AI工厂,以刺激经济增长、促进创新并提升效率。欧洲高性能计算联合体(EuroHPC JU)近期宣布,计划与 17 个欧盟成员国携手打造 7 座 AI 工厂。
工业时代,一个国家的整体实力可以用钢产量来衡量,需要效率很高的钢铁厂;AI时代,国家的竞争力则可以用其生成的智能体、垂域模型、推理服务的数量来评价,而这就需要高效率的AI工厂。
如今的联想正在加紧打造更多高效率的AI工厂,成为AI普惠的重要推手,为加速实施“人工智能+”提供原动力。
本文来自投稿,不代表创造权威IP 赋能创业者——IP百创立场,如若转载,请注明出处:创造权威IP 赋能创业者——IP百创
 微信扫一扫
微信扫一扫 
