


新一年的全球科技圈,主角俨然是DeepSeek。从发布以来,DeepSeek在整个AI产业链上引发一系列连锁反应,无论是OpenAI,还是英伟达,其明显的震惊似乎皆验证着DeepSeek已奇袭成功。
而DeepSeek的初步表现也的确可圈可点,数据显示,上线5天DeepSeek日活跃用户已超过ChatGPT,上线20天的日活达2000万人次以上,已是ChatGPT的23%。当前,DeepSeek成为全球增速最快的AI应用。
在海外一众AI玩家不可置信的同时,国内AI领域一片“锣鼓喧天”:截至目前,阿里云、百度云、腾讯云、字节火山引擎均已正式支持DeepSeek;同时,百度昆仑芯、天数智芯、摩尔线程接连宣布支持DeepSeek模型。
这也标志着全球AI竞速赛中,国产厂商终于又跨出了一步。而DeepSeek的出现,是否为僵化已久的大模型行业破除了一些传统“诅咒”,很多至关重要的细节,其实还值得进一步深究。
DeepSeek出圈是“偶然性”的吗?
纵观当前围绕DeepSeek的几大主要争议,似乎每一点都指向同一个问题:DeepSeek是否真的实现了大模型的技术突破。早在DeepSeek公布其模型训练成本仅为行业1/10时,就有声音质疑,DeepSeek是通过大幅缩减模型参数规模,或依赖母公司幻方早期囤积的廉价算力实现的。
从某种角度来看,这些质疑有迹可循。
一方面,DeepSeek在缩减模型参数规模方面的“激进”有目共睹,另外一方面,DeepSeek背后的幻方确实有一定的算力储存。据悉,幻方是BAT之外唯一能够储备万张A100芯片的公司,有报道在2023年就曾公布过国内囤积超过1万枚GPU的企业不超过5家。
幻方就是其中之一。
但值得一提的是,无论是模型参数规模的缩减,还是算力创新争议都无法否定DeepSeek“小力出奇迹”打法的实质意义。首先,DeepSeek-R1在参数量仅为1.5亿(1.5B)的情况下,在数学基准测试中以79.8%的成功率超越GPT-4等大模型。
其次,轻量化模型天然在推理能力与性能方面表现更出彩,训练和运行成本也更低。据悉,DeepSeek以仅需1/50的价格提供了GPT-4类似的性能,在中小型企业和个人开发者中抢夺了一定的市场地位。
至于幻方对DeepSeek的加成,与其说是一场资本的偶然游戏,不如说是国产大模型成长的必然结果。值得注意的是,幻方量化算是国内第一批闯入大模型赛道的企业,早在2017年,幻方就宣称要实现投资策略全面AI化。
2019年,幻方量化成立AI公司,其自研的深度学习训练平台“萤火一号”总投资近2亿元,搭载了1100块GPU;两年后,“萤火二号”的投入增加到10亿元,搭载了约1万张英伟达A100显卡。
2023年11月,DeepSeek 的首个开源模型 DeepSeek-Coder发布。也就是说,这个引起海外科技巨头集体破防的DeepSeek不是一夜之间的产物,而是国产AI厂商在大模型布局中早晚要走的一步。
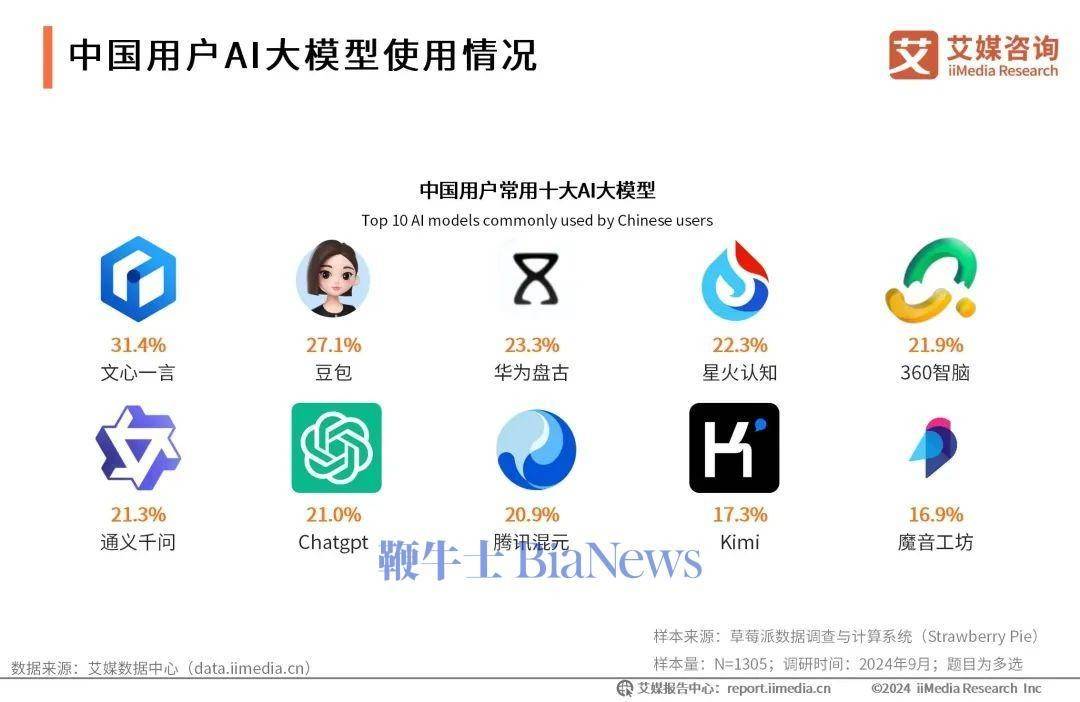
不可否认,当前国内已具备培育“DeepSeek ”的客观条件。公开资料显示,一个全面的人工智能体系正在各方资本的追捧下诞生,国内人工智能相关企业超过4500家,核心产业规模接近6000亿元人民币。
芯片、算法、数据、平台、应用……我国以大模型为代表的人工智能普及率达16.4%。
当然,DeepSeek的技术路径依赖风险始终存在,这也让DeepSeek的出圈多了一丝偶然,尤其“数据蒸馏技术”不断遭受重重质疑。事实上,DeepSeek并非第一个使用数据蒸馏的大模型,“过度蒸馏”甚至是当前人工智能赛道的一大矛盾。
来自中科院、北大等多家机构就曾指出,除了豆包、Claude、Gemini之外,大部分开/闭源LLM蒸馏程度过高。而过度依赖蒸馏可能会导致基础研究的停滞,并降低模型之间的多样性。上海交通大学也有教授表示,蒸馏技术无法解决数学推理中的根本性挑战。
总而言之,这些都在反逼DeepSeeK乃至整个国产大模型赛道继续自我验证,或许,国内还会诞生第二个“DeepSeek”,从现实的角度来看,DeepSeek成功的必然远远大于偶然。
“开源时代”要来临了吗?
值得注意的是,相比于技术之争,DeepSeek也再度引发了全球科技圈对开源、闭源的激烈论证。Meta首席科学家杨立昆还在社交平台上表示,这不是中国在追赶美国,而是开源在追赶闭源。
谈及开源模型,还要追溯到2023年Meta的一场源代码泄露风波。彼时,Meta顺水推舟发布了LLama 2开源可商用版本,顿时在大模型赛道掀起开源狂潮,国内诸如悟道、百川智能、阿里云纷纷进入开源大模型领域。
根据Kimi chat统计,2024年全年开源大模型品牌超过10个。2025年开年不足两个月,除了大火的DeepSeeK之外,参与开源者数不胜数。
据悉,1月15日,MiniMax开源了两个模型。一个是基础语言大模型MiniMax – Text – 01,另一个是视觉多模态大模型MiniMax – VL – 01;同时,NVIDIA也开源了自己的世界模型,分别有三个型号:NVIDIA Cosmos的Nano、Super和Ultra;1月16日,阿里云通义也开源了一个数学推理过程奖励模型,尺寸为7B。
从2023年到2025年,无数AI人才争论不休后,大模型的“开源时代”终于要来了吗?
可以确定的一点是,比起闭源模式,开源模型能在短时间内凭借其开放性获得大量关注。公开资料显示,当年在“LLama 2”发布之初,其在Hugging Face检索模型就有超6000个结果。百川智能方面则显示,旗下两款开源大模型在当年9月份的下载量就超过500万。
事实上,DeepSeek能快速走红与其开源模式分不开关系。2月统计显示,当前接入DeepSeek系列模型的企业不计其数,云厂商、芯片厂商、应用端企业皆来凑了把热闹。在AI需求鼎盛的当前,大模型开源似乎更能促进AI生态化。
但大模型赛道开源与否,其实还有待商榷。
Mistral AI、xAI虽然都是开源的支持者,但它们的旗舰模型目前都是封闭的。国内大部分厂商基本也是一手闭源,一手开源,典型的例子如阿里云、百川智能,甚至李彦宏一度是闭源模式的忠实拥趸。
原因并不难猜测。
一方面,在全球科技领域里开源AI公司都不受资本欢迎,反而是闭源AI企业在融资方面更有优势。数据统计显示,从2020年以来,全球闭源 AI 领域初创公司已完成 375 亿美元融资,而开源类型的 AI 公司仅获 149 亿美元融资。
这对花钱如流水的AI企业而言,其中的差距不是一星半点。
另外一方面,开源AI的定义在这两年愈发复杂。2024年10月份,全球开放源代码促进会发布关于“开源AI定义”1.0版本,新定义显示,AI大模型若要被视为开源有三个要点:第一,训练数据透明性;第二,完整代码;第三,模型参数。
基于这一定义,DeepSeek就被质疑不算真正意义上的开源,只是为了迎合短期声势。而在全球范围内,《Nature》的一篇报道也指出,不少科技巨头宣称他们的AI模型是开源的,实际上并不完全透明。
前几日,受到“打击”的奥尔特曼首次正面承认OpenAI的闭源“是一个错误”,或许,赶着DeepSeek的热度,一场AI界的“口水大戏”又要拉开序幕。
大规模的算力投入即将“暂停”?
这段时间,不少沉迷囤积算力的AI企业因DeepSeek的横空出世遭到冷嘲热讽,英伟达这类算力供应商还在股价上跌了一个巨大的跟头。坦白来说,DeepSeeK在某些方面的确带来了新的突破,尤其在“垄断诅咒”上,缓解了一部分焦虑。
但全球大模型赛道的算力需求依旧不可忽视,甚至DeepSeeK自身都未必能暂停算力投入。
需要注意的是,DeepSeek目前仅支持文字问答、读图、读文档等功能,还未涉及图片、音频和视频生成领域。即便这样,其服务器还困在崩溃的边缘,而一旦想要改变形式,算力需求则会呈爆炸式增长,视频生成类模型与语言模型之间的算力需求差距甚大。
公开数据显示,OpenAI的Sora视频生成大模型训练和推理所需要的算力需求分别达到了GPT-4的4.5倍和近400倍。从语言到视频之间的跨度尚且如此之大,随着各种超级算力场景的诞生,算力建设的必要性只增不减。
数据显示,2010年至2023年间,AI算力需求翻了数十万倍,远超摩尔定律的增长速度。进入2025年,OpenAI发布了首个AI Agent产品Operator,大有要引爆超级算力场景的趋势,这才是关系算力建设是否继续的关键。
据悉,当前大模型发展定义总共分为五个发展阶段:L1 语言能力、L2 逻辑能力、L3 使用工具的能力、L4 自我学习能力、L5 探究科学规律。而Agent位于L3 使用工具能力,同时正在开启对L4的自我学习能力的探索。
根据Gartner预测,到2028年,全球将有15%的日常工作决策预计将通过Agentic AI完成。如果大模型赛道按照规划预想地一路狂奔,从L1到L5,全球各大AI企业对算力的建设更加不会忽视。
到L3阶段,算力需求大概会是多少?
巴莱克银行在2024年10月份的一则报告中预测过,到2026年,假如消费者人工智能应用能够突破10亿日活跃用户,并且Agent在企业业务中有超过5%的渗透率,则需要至少142B ExaFLOPs(约150,000,000,000,000 P)的AI算力生成五千万亿个token。
即便超级应用阶段的到来还遥遥无期,在目前大模型赛道加速淘汰的激烈战场上,也没有一家企业甘愿落后一步。微软、谷歌、亚马逊、Meta、字节跳动、阿里、腾讯、百度……这些海内外的AI巨头只怕会继续花钱赌未来。
另外,DeepSeek最为人称道的莫过于绕开了“芯片大关”。
然而,作为算力产业的基石,相同投入下,优质的算力基础设施往往会提供更高的算力效率与商业回报。《2025年算力产业十大趋势》中提到过,以GPT-4为例,不同硬件配置下其性能会发生显著差异。对比H100和GB200等不同硬件配置驱动GPT-4的性能,采用GB200 Scale-Up 64配置的盈利能力是H100 Scale-Up 8配置的6倍。
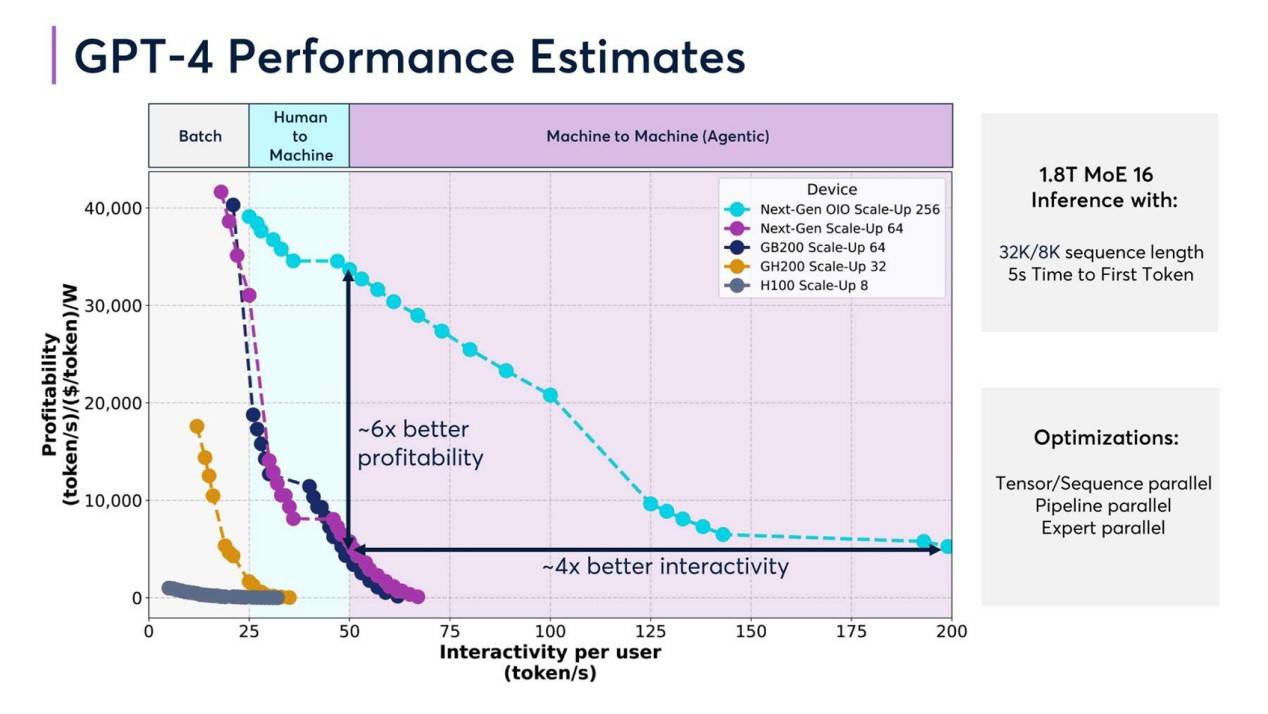
DeepSeek一问三崩的服务器,或许暗示着大模型赛道的“追芯”游戏在算力角逐环节中迟迟未能结束。据悉,2025年,英伟达下一代GPU GB300可能会出现多个关键硬件规格变化,而国内的AI芯片国产化进程也星夜兼程。
种种迹象显示,辛苦的算力建设一时半会无法停止,反而更卷了。
道总有理,曾用名歪道道,互联网与科技圈新媒体。本文为原创文章,谢绝未保留作者相关信息的任何形式的转载。
本文来自投稿,不代表创造权威IP 赋能创业者——IP百创立场,如若转载,请注明出处:创造权威IP 赋能创业者——IP百创
 微信扫一扫
微信扫一扫 